
LLM을 이용하여 영화 자막 번역하기
LLM을 이용하여 영화의 영문 자막을 한글 자막으로 번역 작업해 보았다.
동기
전에 개봉했었던 영화를 보고 싶어서 해당 영화는 다운받았는데 비인기 영화라서 불행히도 자막이 없었다. 애용하는 SMPlayer에서 자막을 검색해 보니, 한글 자막은 없었지만 해당하는 영문 자막은 다운받을 수 있었다.
아주 오래 전에 브래드 피트가 주연한 영화 “조 블랙의 사랑 (Meet Joe Black)”을 직접 한땀 한땀 한글로 번역해서 자막 파일을 완성한 적은 있었는데, 이번에는 요즘의 트렌드인 AI를 활용하여 영문 자막을 한글 자막으로 변환해 보기로 하였다.
자막 편집기에서 번역
나는 자막을 편집할 일은 거의 없긴 하지만, 자막을 편집할 때는 Subtitle Edit 툴이 좋은 것 같다. (전에 한 번은 이걸로 비디오에 overlay 된 타국어 자막을 툴이 지원하는 OCR 기능을 사용하여 srt로 뽑아내기도 하였음)
그런데 이번에 Subtitle Edit에서 기능을 찾아보니 자체적으로 자막을 번역해 주는 기능을 지원하고 있다는 것을 발견하였다. Google APIv1을 사용하거나, local LLM 또는 cloud LLM을 지원하였다.
다만 Google APIv1은 APK key 입력 없이 바로 사용 가능하였지만, 번역 품질이 좋지는 않았다. Cloud LLM을 사용하면 품질이 좋겠지만 유료 계정에서 지원하는 API key가 필요하여서, local LLM으로 테스트 해 보았다.
Subtitle Edit는 Local LLM으로 Ollama, LM Studio 등을 지원하는데, “Auto-translate” 메뉴를 실행한 후에 LM Studio를 선택하면 아래 캡쳐 예와 같이 URL 주소가 표시된다.
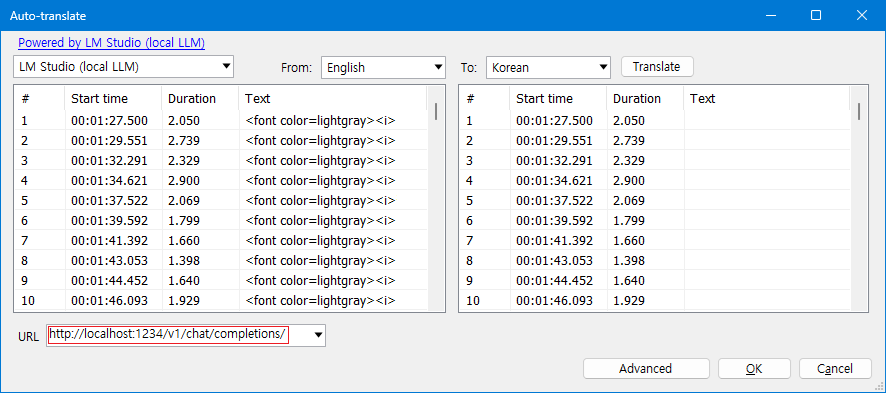
Local LLM 설치
먼저 LM Studio를 설치한 후에, LM Studio에서 사용하고자 하는 모델을 설치/실행하면 된다. 일단 테스트로 내 환경에 적합한 LGAI-EXAONE/EXAONE-3.5-7.8B-Instruct-GGUF 모델을 설치해 보았다. (그런데 테스트 결과 번역의 품질은 기대보다 좋지 못했고, 결국 손번역했다. 😡 아무래도 더 많은 파라미터의 LLM을 사용해야 할 것 같다)
모델을 실행하게 되면 http://localhost:1234/v1/chat/completions/ URL로 접속할 수 있고, Subtitle Edit에서도 이 URL을 사용해서 자막 파일을 번역하게 된다.
subLLM 이용
추가로 구글링 하다 보니 subLLM(SubtitleLLM)이라는 오픈소스를 발견하였다. 이 툴은 LM Studio의 Rest API를 이용하여, Python 기반으로 Local LLM을 이용하여 자막 파일을 번역해 준다.
아래와 같이 subLLM 패키지를 설치한다.
git clone https://github.com/kmelonLab/subLLM.git
pip install requests python-dotenv
이후 setting.env 설정 파일에서 아래 예와 같이 LLM URL, 사용할 LLM 모델, 자막 소스 언어, 자막 타겟 언어, 입력 자막 파일 경로, 출력 자막 파일 경로를 설정한다.
LM_API_URL=http://localhost:1234/v1/chat/completions
LM_MODEL=lgai-exaone/exaone-3.5-7.8b-instruct
SOURCE_LANG=en
TARGET_LANG=ko
SEARCH_PATH=./subtitles
OUTPUT_PATH=./output
나는 prompt_template.txt 파일을 변경하지 않고 사용했는데, 아무래도 번역의 품질을 올리려면 prompt_template.txt 파일에 추가로 AI에게 번역 지침을 주어야 할 것 같다.
이제 아래와 같이 실행시키면 된다.
python app.py
그런데 번역이 완료되기 전까지는 상당히 시간이 오래 걸리는데 반하여, 출력 파일은 번역이 바로 바로 반영되지 않고 모두 완료되어야 반영되는 문제가 있어서, translate_subtitles 함수에서 아래와 같이 수정하여 번역 결과가 각 index 마다 바로 출력 파일에 저장되도록 하였다.
def translate_subtitles(input_path: Path):
...
cleaned_base = clean_filename_with_llm(input_path.name)
cleaned_base = sanitize_filename(cleaned_base)
final_name = apply_filename_rules(cleaned_base + input_path.suffix)
relative_path = input_path.relative_to(Path(SEARCH_PATH))
output_path = Path(OUTPUT_PATH) / relative_path.parent / final_name
output_path.parent.mkdir(parents=True, exist_ok=True)
f = open(output_path, "w", encoding="utf-8")
for entry in entries:
try:
translated = translate_text(entry["text"])
print(f"{entry['index']} input text: " + entry["text"])
print(f"{entry['index']} result text: " + translated + "\n")
entry_text = f"{entry['index']}\n{entry['time']}\n{translated}\n"
except Exception as e:
print(f"Error translating line {entry['index']}: {e}")
entry_text = f"{entry['index']}\n{entry['time']}\n{entry['text']}\n"
f.write(entry_text + "\n")
f.close()
맺음말
이번 실험에서는 AI 자동 번역 결과가 만족할 만한 수준은 아니었는데, 이는 사용한 LLM 모델이 충분히 좋지 못했고, 상세한 번역 지침도 주지 않아서인 것 같다. 이번에 간단히 실험하면서 가능성은 충분한 것으로 확인했고, 이후 제대로 조건만 맞으면 꽤 고품질의 번역을 얻을 수 있을 것 같다.